7.10 Implement recovery strategies
- Backup storage strategies
- Recovery site strategies
- Multiple processing sites
- System resilience, high availability, Quality of Service (QoS), and fault tolerance
A backup utility backs up data. The utility could be set to operate automatically or manually. The utility may back data from a server, computer, network video recorder or other device. The back-ups can be stored on a storage appliance, tape, removable drive, or in the cloud.
It is important to back up data regularly. A large organization may have an individual or group dedicated to maintaining back ups.
- Back up all data regularly (incremental and full back ups)
- Verify that the data has been backed up
- Retain a copy of the backed-up data on site and retain a copy off site (in case of a natural disaster)
When planning a back-up strategy, think about whether it allows the organization to resume normal operations, and how quickly. The speed of the recovery should be weighed against the cost of the back-up strategy. Disaster recovery is discussed in more depth further on.
There are four main types of back ups: Full, Differential, Incremental, and Snapshots. The type of back up affects the way that data is backed up and the way that data is restored.
A Full backup is a backup of the entire set of data. The first time a back up is performed, a full back up must be performed. An organization may perform a full back up once per week or once per month. A Bare Metal back up is a full backup of a logical drive, which includes the server operating system. A Bare Metal back up can be used to restore the server’s operating system and applications, whereas a normal full back up may contain only user-generated data.
A Differential Backup is a backup of the data that has changed since the last full backup. The organization must be careful to ensure that it is able to accurately keep track of data that has changed.
An Incremental Backup is a backup of the data that has changed since the last Full Backup or Incremental Backup. Why use Incremental or Differential backups? Which is better? How does it work?
Consider an organization that performs Full and Differential backups. If the organization performed
- A full back up on Monday (all the data is backed up)
- A differential back up on Tuesday (the data that was changed between Monday and Tuesday is backed up)
- A differential back up on Wednesday (the data that was changed between Monday and Wednesday is backed up)
- A differential back up on Thursday (the data that was changed between Monday and Thursday is backed up)
- A differential back up on Friday (the data that was changed between Monday and Friday is backed up)
Consider an organization that performs Full and Incremental backups. If the organization performed
- A full back up on Monday (all the data is backed up)
- An incremental back up on Tuesday (the data that was changed between Monday and Tuesday is backed up)
- An incremental back up on Wednesday (the data that was changed between Tuesday and Wednesday is backed up)
- An incremental back up on Thursday (the data that was changed between Wednesday and Thursday is backed up)
- An incremental back up on Friday (the data that was changed between Thursday and Friday is backed up)
An incremental backup generates less data than a differential backup, but it is faster to restore data from a differential backup. If the organization uses differential backups and experiences data loss on Thursday
- It must restore the data that from Monday’s full back up
- Then it must restore the data from Thursday’s differential back up
If the organization uses incremental backups and experiences data loss on Thursday
- It must restore the data that from Monday’s full back up
- Then it must restore the data from Tuesday’s incremental back up
- Then it must restore the data from Wednesday’s incremental back up
- Then it must restore the data from Thursday’s incremental back up
Notice that in every process, the full backup must first be restored. In the case of a differential backup, the most recent differential backup must then be restored. In the event of an incremental backup, all the incremental backups created after the full backup must be restored. An incremental backup takes less time to create than a differential backup but takes longer to restore.
If the organization creates a full backup each week, then the organization would (at most) restore six incremental backups. If the organization creates a full backup each month, then they would have to restore up to thirty incremental backups.
Why use a combination of full and incremental back ups? Why not perform a full back up every day? A full back up may take a long time to run and take up a large amount of space. What if the full back up takes 28 hours to run – then we can’t create a full back up every day?
What if the organization maintains 10,000TB of data, but only changes approximately 100TB per week? Should the organization generate 70,000TB of data back ups every week? If the back up location is in the cloud, then the organization will need to pay for 70,000TB of storage and bandwidth each week.
A snapshot is an image of a virtual machine or a disk. A snapshot allows an organization to restore a server or application to a previous state in the event of a hardware failure or corruption of the software. The benefits of a snapshot
- A server can be restored to an exact state, which could include its operating system, applications, configuration, and data.
- It would otherwise take hours or days to restore a server to its original state, especially if the application installers are no longer available, or if the installation process was not documented
- If a user makes changes to the system that cause damage or undesired operation, the system can be restored to a working state
It may not always be possible to take a snapshot. A hypervisor can take a snapshot of a live virtualized system while it is running, but it may not be possible to image a physical system without shutting it down (which could affect operations).
How often does an organization need to perform a back up? The organization must weigh the cost of the back up against the cost of the potential data loss, and the time that it will take to restore the data.
- If the back up is performed daily, the organization could risk losing a day’s worth of data.
- If the back up is performed weekly (say on a Monday), and data loss occurs on a Friday, the organization could lose all the data generated between Monday and Friday.
- If the back up is performed in real time (i.e. replicated to another site), then the organization will not lose any data, but replication is expensive.
We don’t need to have the same back up strategy for the entire organization. Some data may be more valuable than others. We can also archive old data that we maintain for historical purposes but don’t access or don’t access often.
What are all the methods that we can use to back up our data?
- Cloud. There are many services including Amazon S3 and Amazon Glacier. Back ups can be configured automatically.
- Replication over SAN (Storage Area Network). When having multiple locations, the SAN can replicate the data to each location. This is good for massive volumes of data.
- NAS (Network Attached Storage). This is good for medium sized volumes of data (up to 10 TB)
- Tape Library. A tape library is a system that automatically backs up the data onto magnetic tapes. We can insert new tapes and eject back up tapes to store them in an off-site location. Tape libraries range in size. This can be good for medium to large volumes of data.
- Disk Cartridge. A disk cartridge is like a removable hard drive that you can store. Disk cartridge back ups are good for small volumes of data.
- Removable Disk (USB Drive). You can connect a USB drive and back up the data manually
We should look at the following for each type of data
- How much money will the organization lose if it is lost?
- How much time (in hours or days) can the organization wait before having the data restored?
- What is the volume of data to be backed up?
- Based on this information
- We know how much we can afford to spend on the data back up
- We know how much data needs to be backed up in GB or TB or PB
- We know how quickly we need to restore our data. The time to restore the data is the time to bring the data back up to the facility and the time to complete the restoration process.
- If the back up is in the cloud, then we can figure out the bandwidth we require
- If the back up is at a storage vendor, then we can figure out the maximum distance of the storage location
- We can figure out how often to run the back up and whether we can use incremental or differential back ups
- We can decide whether the back up is online or offline. An online back up is one that is physically or logically connected to the system. An offline back up is one that is on a storage medium such as a magnetic tape, or a hard disk cartridge.
It is usually faster to restore data from an online system because the data is already accessible. We just need to copy it. The offline back up must be physically connected to the system and then copied. If it is offsite, then it must first be brought to site, and then connected.
- If the back up is in the cloud, then we can figure out the bandwidth we require
- We know how much we can afford to spend on the data back up
- What is the organization’s risk appetite?
- The question is, does the organization like to spend money to avoid risks?
- If the organization has a high-risk appetite, then they may not want to spend the money on multiple back ups.
- A common strategy is called 3-2-1. – we have three copies of the data, and two types of media, with one off site. What you should do
- One copy in production (this is the live data)
- Two copies in the cloud, each in a separate region
- Two physical copies as back up. Each one should be a separate type of medium.
- If we use a SAN with physical replication, then that might be considered the off-site physical copy
- If not, then one copy might be on a tape and the second might be on a hard disk drive
- If we use a SAN with physical replication, then that might be considered the off-site physical copy
- One physical copy should be stored on site and one physical copy should be stored off site (either at another office or at a vendor like Iron Mountain)
- One copy in production (this is the live data)
- The question is, does the organization like to spend money to avoid risks?
A Recovery Site is a location that a company can use to resume operations when their main site is harmed. The recovery site might be an office, a factory, or a data center. It contains all the technology and equipment that the company requires to resume operations should their existing facilities be damaged or inaccessible.
An organization must weigh the cost and benefit of the type of recovery site they will operate. A hot site allows an organization to resume operations immediately (without a cost to its business) but is more expensive. A cold site forces an organization to wait to resume operations (at a substantial cost) but is much cheaper.
There are three types of recovery sites
- A hot site is a site that is continually running. With the use of a hot site, an organization has multiple locations that are operating and staffed. For example, an insurance company may have a call center in New Jersey, a call center in Florida, and a call center in California. The insurance company staffs all three centers 24/7. If the California call center is affected by an earthquake, the insurance company diverts calls to New Jersey and Florida, and operations are not disrupted.
In the case of a data center, the organization will maintain data centers in multiple geographic locations. These data centers are connected to each other over WAN links. Data is replicated across multiple data centers, so that damage to one data center does not compromise the data. For example, an insurance company stores customer data in data centers at California, Utah, and Virginia. The Virginia data center is hit by a tornado, but all the data has been replicated to the other two centers. The organization and its customers can continue accessing their data.
A hot site is expensive to maintain. In the example of the insurance company, they can staff the three sites cost-effectively. A smaller organization (such as a restaurant or warehouse) that operates out of a single location may not find it cost-effective to operate a second site.
We must ask how hot is the hot site? Is data replicated to the hot site instantly or is there a delay? If there is a delay, we might manually take the remaining data from the primary site to the hot site, or we might accept the data loss. - Some vendors sell hot sites. We might share a hot site with other organizations to reduce costs. If we do that, it would be cheaper, but the hot site might be crowded in a disaster.
- A cold site is a location that does not contain staff or equipment. An organization hit with a disaster must send employees to the cold site, bring in supplies, and configure equipment. The cold site does not contain any data; the organization must restore its data from back up.
A cold site is cheaper to operate than a hot site. In the event of a disaster, the cold site can be used to operate the business. The cold site may be an empty office, an abandoned warehouse or a trailer.
Companies such as Regus provide immediate short-term office space in the event of a disaster. - A warm site is a compromise between a cold site and a hot site. A warm site may contain some hardware and preconfigured equipment. The organization may need to bring in staff and/or specialized equipment for the warm site to become operational. The warm site may contain copies of data, but they will not be current.
- A Mobile Site is a recovery site that is inside a trailer. We might keep a bunch of mobile sites that can be deployed anywhere we want.
- A Service Bureau is a company that owns cloud computing and workstations. We might rent capacity from a service bureau during a disaster. The service bureau might be available on an as available basis during the disaster, or we might pay them a retainer so that they can guarantee capacity for our organization. We might contract with service bureaus that are local and ones that are far away.
- A Mutual Assistance Agreement (MAA) is where we make a deal with another company. We help them in the event of a disaster and they help us in the event of a disaster. This won’t cost us much and we can share the burden of maintaining a hot or warm site.
The disadvantage of an MAA is that the other organization might refuse to assist us during the actual disaster. If both organizations are in the same region, they may both suffer from the same disaster, and not be able to provide each other with assistance. Further, we may not want to share our data with a competitor.
Fault Tolerance
Fault Tolerance is the ability of the system to continue operating even when encountering an error. An example of a fault tolerant system is a RAID array. If a single drive in a RAID array fails, the system continues to operate without data loss.
Fault tolerance is expensive, and the organization must weigh the cost of fault tolerance against the cost of not having it (data loss, disruption to its operations, damage to its reputation).
High Availability is the state that Fault Tolerance gives us. Fault Tolerance is simply a design goal that results in a system with High Availability.
High Availability means that the system continues to operate even when there is a disruption.
A Single Point of Failure (SPOF) is a system component that could cause the system to fail, if it failed. System Resilience means that the system continues to provide services even when it experiences an event.
Within a single server, we can implement RAID (Redundant Array of Independent Disks) to protect against the failure of a single drive. There are multiple versions of RAID, and each has benefits and drawbacks.
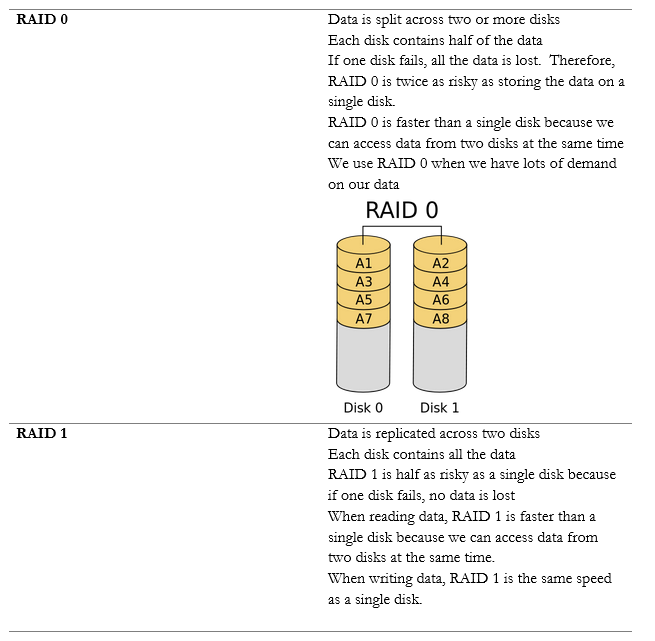
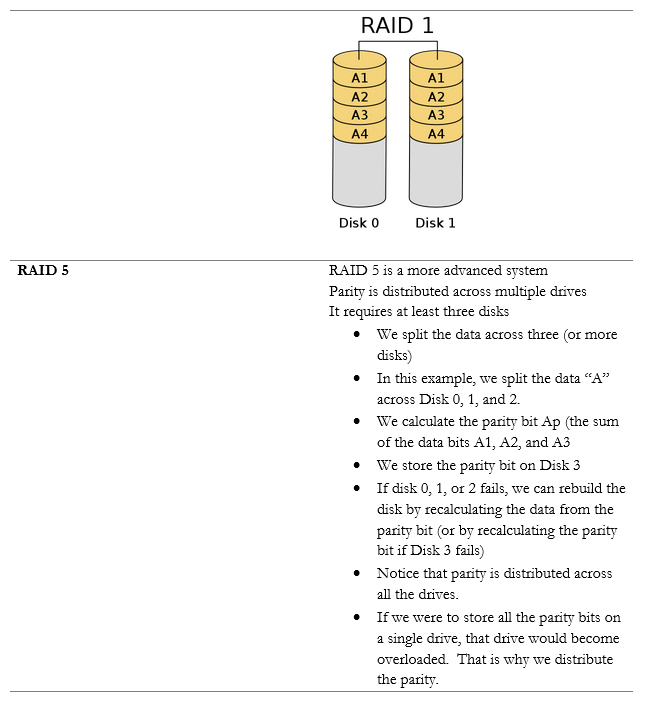
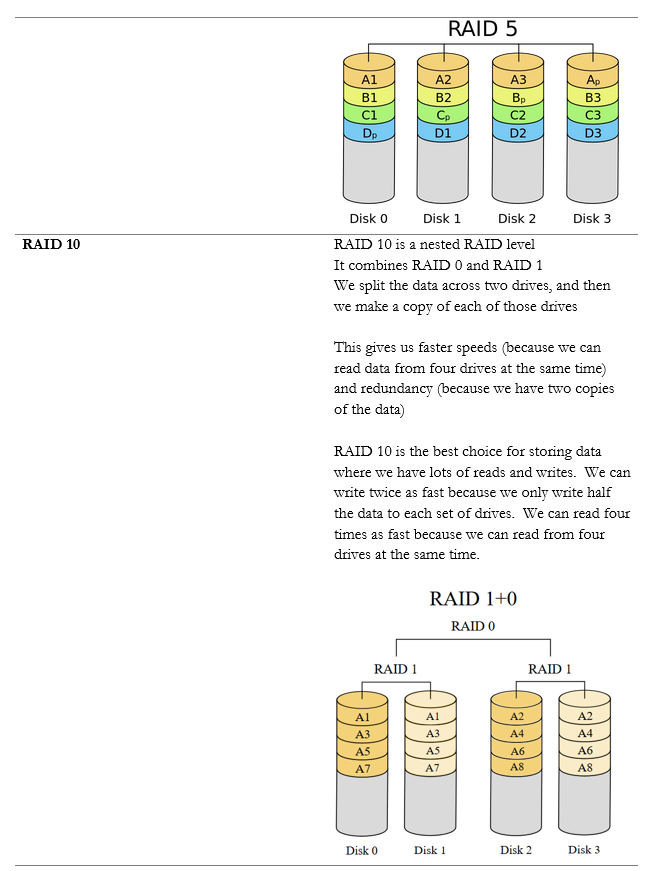

RAID makes the disk storage fault tolerant, but what if we want to take it one step further?
When an organization has lots of data, it is more cost effective to store it on a storage appliance. A storage appliance is basically a server that just stores data. It doesn’t contain expensive processing components. It is also designed to be fault tolerant.
Below is a storage appliance with 24 hard disk drives. We can create multiple shared drives on the storage appliance and then map them to our servers. Then our servers can store their data on this storage appliance just as if it was a physically connected hard disk drive.

The storage appliance implements RAID by default, but what if the storage appliance fails? We can install multiple storage appliances. We then create a pathway to each one. The server now can store its data in multiple locations. This is known as multipath.
Consider that we have three servers:
Server A has a private IP of 10.0.0.1
Server B has a private IP of 10.0.0.2
Server C has a private IP of 10.0.0.3
The public IP address is 11.11.11.11
Servers A, B, and C communicate with each other over their private IPs 10.0.0.1, 10.0.0.2, and 10.0.0.3. The servers all set 11.11.11.11 as their public IP, and then elect one server to respond to requests. For example, Server A, B, and C choose to have Server B respond to all requests on 11.11.11.11. If Server B is overloaded, it may communicate this fact with Server A and C (over their private IPs), which designate Server A to temporarily respond to requests on 11.11.11.11.
The servers continually ping each other to ensure that all the servers are functional. This form of communication is known as a heartbeat. If Server B were to stop responding within a specific period, Server A and Server C would choose to designate Server A to respond to new requests.
The algorithm used to determine which server would respond will vary from scenario to scenario.
NIC Teaming is a form of load balancing that allows a server to maintain multiple network connections. Remember that a server can have multiple network interfaces. Consider the following server. I have connected it to two switches. Each interface is assigned a different IP address (192.168.0.10 and 192.168.0.11).
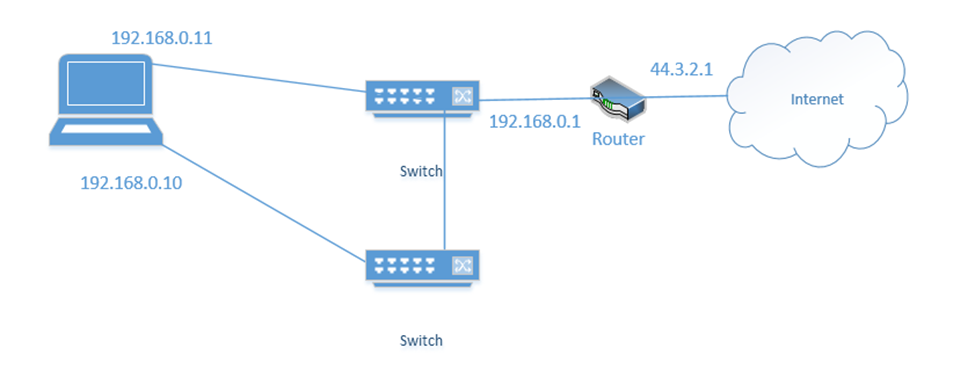
You may think that it is fault tolerant because it has two connections. If 192.168.0.11 fails, the server will continue to accept traffic on 192.168.0.11, but this is not fault tolerant because devices connected to the server on 192.168.0.10 will lose their connections. Some clients know to connect to the server through 192.168.0.10 and some know to connect through 192.168.0.11. So, what can we do?
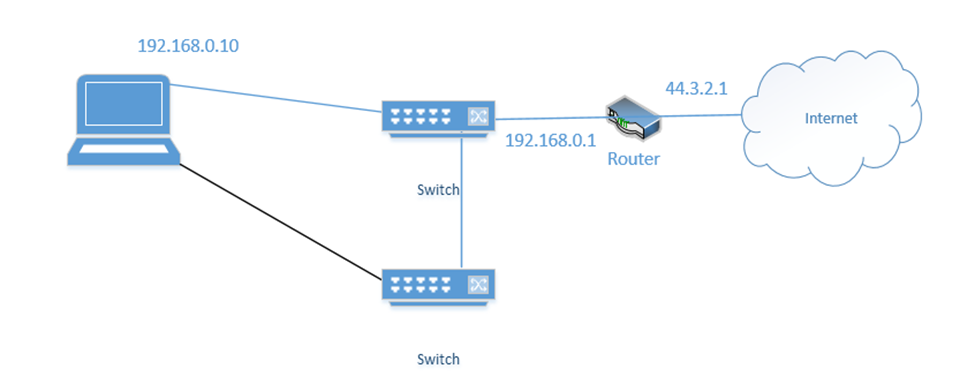
We group the network interfaces into a “team”. We assign the team a single IP address even when the server is connected to multiple switches. This is known as Switch Independent Teaming. One interface is active, and one is passive. The active interface assumes the IP address. When the active interface fails, the passive interface takes over and assumes the IP address.
Right now, the bottom link is active with IP address 192.168.0.10
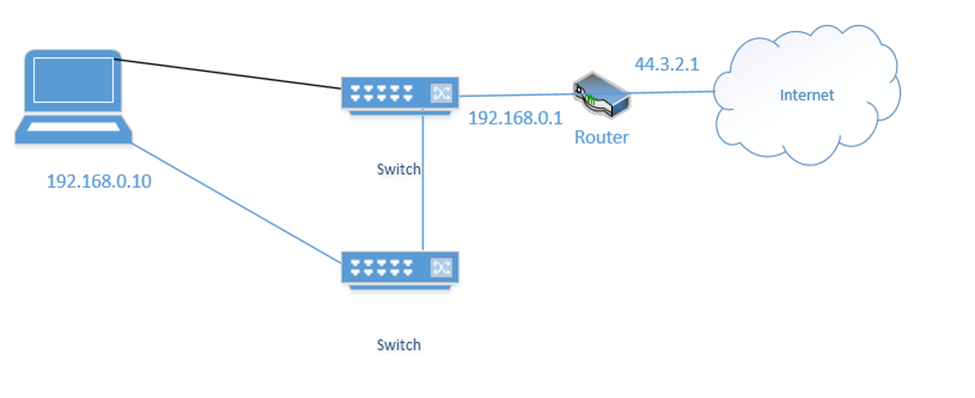
If the bottom link fails, the server assigns 192.168.0.10 to the top link
Below is a setup I have made. On the right, we have two internet connections (one broadband and one cellular). Each internet connection connects to both of the firewalls. Each firewall connects to both routers. Each router connects to both switches. Half of the wireless access points connect to one switch and half connect to the other switch. The switches connect to each other, and the routers connect to each other.
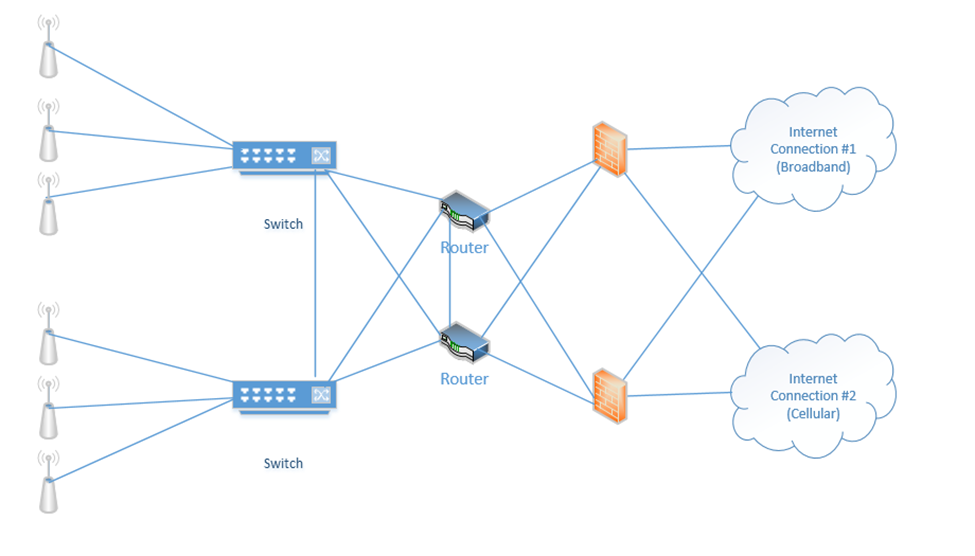
When things are operating normally, the data probably uses the black route. That is, the internet connection #1 is used, the top firewall is used, the top router is used, and both switches are used.
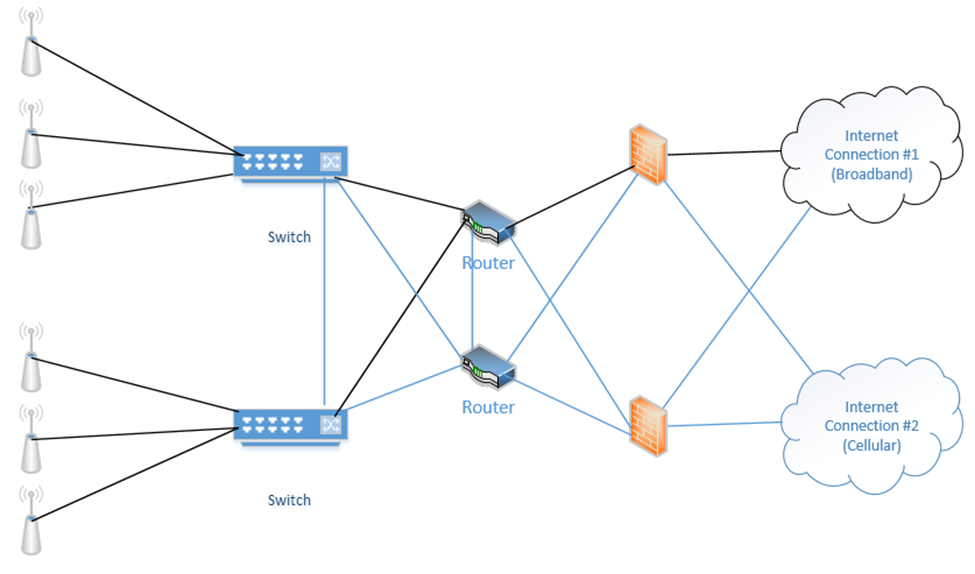
If an internet connection fails, a router fails, and/or a firewall fails, the system will continue to operate. Why? Because we removed many single points of failure.
Our devices should each have two power supplies, if possible (the ISP modems usually will not have more than one power supply). We can connect each device to two separate UPSs.
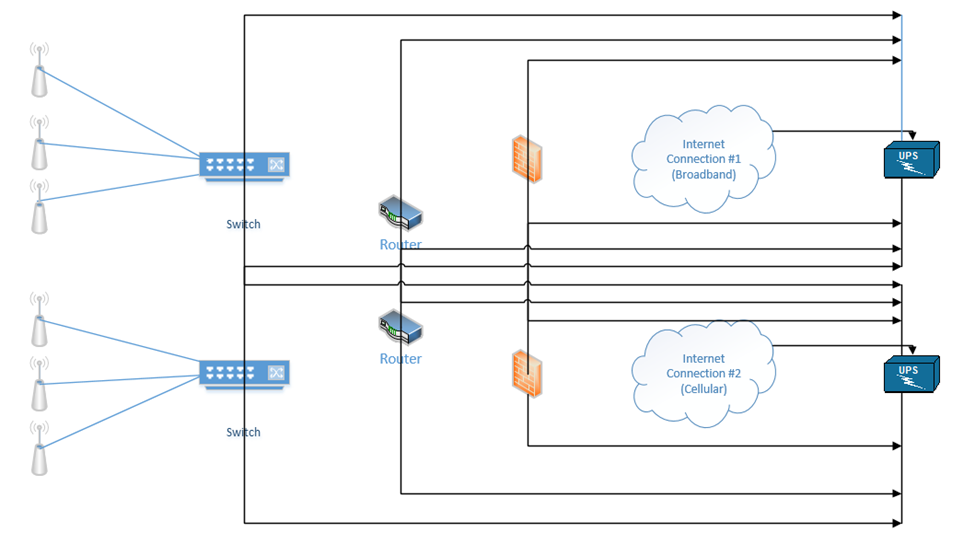
Depending on the size of the building and/or infrastructure, we may have some or all of the following
- Uninterruptible Power Supply (UPS) – Between the electrical supply and our equipment, we install a UPS or Uninterruptable Power Supply. In simple terms, a UPS is a giant battery. We connect our equipment to the UPS, and we connect the UPS to the municipal power supply. If the municipal power supply fails (a blackout) or decreases (a brownout), then the UPS takes over. The UPS must be able to take over so quickly that our equipment doesn’t notice and shut down. A UPS may also protect against power surges (when too much power rushes into the building, which could damage the equipment). When the municipal power supply is active, the UPS charges its batteries. When it fails, the UPS supplies the connected equipment from the battery.
The size of the UPS that we need depends on the quantity and type of equipment that we have. When you purchase electrical equipment, the manufacturer must specify how much power it consumes (in Watts). A Watt is a unit of energy consumption. Equipment may use more power when it is busy than when it is idle. Therefore, we should calculate the maximum power consumption of all our equipment.
A UPS is rated in Watts. We should not exceed the Wattage rating of the UPS. We should consider purchasing a UPS that can handle 20% to 50% more capacity than we are consuming, in case we need to add new equipment in the future. Also, no UPS is 100% efficient.
The second factor we should consider is the runtime. The runtime tells us how long the UPS can power our equipment for. We should think about how much time we need to properly shut down our equipment. If shutting down the equipment is not an option, then we should think about how much time we need until our power generator takes over.
A UPS can be a small unit that sits on a shelf, a rack-mounted unit, a unit that is the size of a rack, or an independent unit.
This is a small UPS. It might sit on the floor under your desk. It is good for powering a single device or a few small devices. It costs approximately $50. If we have a single switch or router, or an important computer, this might be acceptable.

This is a rack-mount UPS. It takes up 2Us in a rack and is good for powering a rack full of devices. It costs approximately $2000. If we have a single rack full of equipment, this might be acceptable. It would be a good idea to purchase two separate UPSs for redundancy.

This is a full rack UPS. It comes as a full rack and can sit in an MDF or IDF. If we have multiple racks full of equipment, this might be a better solution than using multiple 2U UPSs.

This UPS requires an electrician to install. Equipment will not connect directly to this UPS. Instead, this UPS is connected to an electrical panel. From the electrical panel, we install multiple electrical circuits. We then connect our equipment to the electrical circuits.

UPSs can be much larger. A large building such as a school, shopping mall, or hospital may have a UPS that is connected to the electrical panel and electrical outlets.

- Generator – What if we have a power outage that lasts three days and we need to keep operating, but our UPS only lasts one hour? We install a power generator, which is a device that can produce electricity. When the power outage takes place, the UPS supplies power from its batteries, and the generator produces new power to recharge those batteries.
A typical power generator burns diesel. Generators can be portable or fixed. It is better to have a power generator and not need it then to need it and not have it. The power generator should be maintained regularly to ensure that it is operating and that it contains an adequate supply of fuel. The organization should also make sure that it has a contract to receive additional fuel deliveries during a long power outage.
If we don’t have a UPS, the power generator can feed power directly to the building’s electrical distribution. This isn’t a good idea because if the generator fails or takes time to start up, then our systems will stop operating.
The generator requires regular maintenance and testing.

- Power Distribution Units (PDUs) – Finally, to avoid any single point of failure, it is important to select network devices and servers with redundant power supplies. If we have two UPSs, we connect one power cord from each device to the first UPS, and we connect the second power cord to the second UPS. That way, if a UPS fails, the devices continue to receive power. Most devices with dual power supplies offer power supplies that are hot swappable. Electronics use power that is DC (Direct Current), while a UPS or municipal power supply provides power in AC (Alternating Current). An electronic device will contain an adapter that converts from AC to DC. This adapter may fail during operation. When it is hot swappable, it can be replaced even while the device is powered on.
In a data center with hundreds of devices, it can become difficult to identify which plug goes to which power supply. As a result, manufacturers produce power cables in different colors such as red, green, and yellow. You can use these cables to tell different circuits apart. You can also use them to color code different types of devices such as routers, switches, firewalls, etc..
A Managed PDU can be connected to our network. Some features of a managed PDU - We can remotely activate or deactivate an outlet. This allows us to remotely reboot a connected device that is not responding.
- We can determine whether an outlet is functioning, and how much power it is drawing.

Trusted Recovery
If our system fails and recovers, we want to make sure that it is just as secure as when it crashed.
- A Fail-Secure system will fail but default to a secure state (no access granted). Electronic door locks should always fail secure. If the power fails, or if the lock fails, then the door should stay locked.
- A Fail-Open system will fail but default to an open state (all access granted). A fire escape for example might Fail-Open so that people aren’t trapped inside.
- When a system recovers and reboots, it should do so in a nonprivileged state so that normal users can log in
There are other types of recovery
- Automated Recovery – the system will automatically recover after a failure.
- Automated Recovery without Undue Loss – the system will automatically recover after a failure and specific objects are protected to ensure they are not lost. Many databases use a tool called a write ahead file, which tracks changes before they are written to the main database file. This ensures that the changes to the database are either fully written or not. If the database crashes during the write, the changes can be reversed.
- Manual Recovery – an administrator might need to manually recover the system after it fails. This is a good option when a quick recovery is not needed but when we must check the system for issues before restoring it.
- Function Recovery – the system will automatically recover specific functions after it fails.
Quality of Service
Quality of Service (QoS) is a concept regarding how well a specific network service is performing. We can measure different things like bandwidth (speed), packet loss (what percentage of data is reaching its destination), jitter (does the data we send show up in the same order or is it all mixed up).
QoS is most important in VoIP and live video applications. Why? Remember that TCP follows a three-way handshake? If I send you a file, you must acknowledge that you received it. If a computer sends a packet to another computer, the recipient must acknowledge receipt. If something happens to the packet along the way, it could always be retransmitted. A small amount of packet loss is a minor annoyance. Maybe the users don’t even notice. If the packets don’t arrive in the correct order, the receiving computer puts them back together.
With VoIP and live video however, imagine that each word you say is a packet. The phone or video screen on the other side must play those packets back to the other party in real time. It doesn’t have time to correct for errors. If some packets go missing, then the person on the phone with you doesn’t hear some of the words you said. If packets arrive in the wrong order, then the words you say are heard in the wrong order on the other side. Too much of that and the users become frustrated.
What are some things we measure when we say Quality of Service?
- How much bandwidth are we getting? This is known as throughput, or Goodput. Goodput is the useable bandwidth (actual bandwidth minus overhead for protocols). It’s like the weight of the mail without the envelopes.
- Packet loss. What percentage of packets are lost in transmission?
- Errors. What percentage of packets arrive without errors?
- Latency. How long does a packet take to reach its destination?
- Out-of-Order delivery. Are the packets arriving in the same order that they were sent?
A customer and his internet service provider may enter into an agreement to obtain a specific level of service. How can the ISP meet this obligation? Over-provision the network so that it has much more capacity then is required.
But a single service provider doesn’t own the entire internet! Your traffic first reaches your ISP and then it reaches your ISP’s ISP, and then your ISPs ISPs ISP…therefore, the ISPs must negotiate a way to prioritize certain types of traffic so that customers who pay more experience better service.