3.3 Explain high availability and disaster recovery concepts and summarize which is the best solution
- Load Balancing
- Multipathing
- Network Interface Card (NIC) Teaming
- Redundant Hardware/Clusters
- Switches
- Routers
- Firewalls
- Facilities and Infrastructure Support
- Uninterruptible Power Supply (UPS)
- Power Distribution Units (PDUs)
- Generator
- HVAC
- Fire Suppression
- Redundancy and High Availability (HA) Concepts
- Cold Site
- Warm Site
- Hot Site
- Cloud Site
- Active-Active vs Active-Passive
- Multiple Internet Service Providers (ISPs) / Diverse Paths
- Virtual Router Redundancy Protocol (VRRP) / First Hop Redundancy Protocol (FHRP)
- Mean Time to Repair (MTTR)
- Mean Time Between Failure (MTBF)
- Recovery Time Objective (RTO)
- Recovery Point Objective (RPO)
- Network Device Backup/Restore
- State
- Configuration
In the previous section, we mentioned disaster recovery and general ideas for keeping a business operating even in the event of a disaster. We are now going to look at some specific ways that this can be accomplished.
Fault Tolerance is the ability of a system to continue operating even when encountering an error. An example of a fault tolerant system is a RAID array. RAID is a system where multiple hard disk drives in a server store the same data. If a single drive in a RAID array fails, the system continues to operate without data loss. We can then replace the failed drive, and the server will copy the data to it.
Fault tolerance is expensive, and the organization must weigh the cost of fault tolerance against the cost of not having it (data loss, disruption to its operations, damage to its reputation).
High Availability is the state that Fault Tolerance gives us. Fault Tolerance is simply a design goal that results in a system with High Availability.
High Availability means that the system continues to operate even when there is a disruption.
One system that provides High Availability in a server environment is VMware VSphere – Fault Tolerance. VSphere is a hypervisor that allows a user to create multiple virtual servers on a physical machine. High Availability by VMware distributes the virtual server workload on multiple physical machines, which can be in different geographic locations. In the event of a failure of a server component, or even a physical server, the system continues to operate as normal.
For example, I could set up a virtual database server that is physically hosted on a server in Florida and a server in Oregon. Users think that they are connecting to a single physical server but if a hurricane destroys the server in Florida, VMware will ensure that the server in Oregon continues to host the server without any disruption.
We can ensure availability by reducing or removing single points of failure.
We can calculate the percentage of time that a system is available for. The percentage might be expressed as a number of “nines”. For example, if the system is available 99% of the time, it is called “two nines”. If the system is available for 99.999% of the time, it is called “five nines”. Below is a table of the most common uptimes.
| Availability % | Downtime per year | Downtime per quarter | Downtime per month | Downtime per week | Downtime per day (24 hours) |
| 99% (“two nines”) | 3.65 days | 21.9 hours | 7.31 hours | 1.68 hours | 14.40 minutes |
| 99.9% (“three nines”) | 8.77 hours | 2.19 hours | 43.83 minutes | 10.08 minutes | 1.44 minutes |
| 99.99% (“four nines”) | 52.60 minutes | 13.15 minutes | 4.38 minutes | 1.01 minutes | 8.64 seconds |
| 99.999% (“five nines”) | 5.26 minutes | 1.31 minutes | 26.30 seconds | 6.05 seconds | 864.00 milliseconds |
| 99.9999% (“six nines”) | 31.56 seconds | 7.89 seconds | 2.63 seconds | 604.80 milliseconds | 86.40 milliseconds |
| 99.99999% (“seven nines”) | 3.16 seconds | 0.79 seconds | 262.98 milliseconds | 60.48 milliseconds | 8.64 milliseconds |
| 99.999999% (“eight nines”) | 315.58 milliseconds | 78.89 milliseconds | 26.30 milliseconds | 6.05 milliseconds | 864.00 microseconds |
| 99.9999999% (“nine nines”) | 31.56 milliseconds | 7.89 milliseconds | 2.63 milliseconds | 604.80 microseconds | 86.40 microseconds |
When a system is down for planned maintenance, that time is not factored into the downtime calculation because users are notified in advance, and the maintenance is scheduled after hours when few users are likely to be logged in (on a Saturday night for example).
Some ways that we can eliminate single points of failure in a network
- Load Balancing – a load balancer is a device that takes traffic and distributes it to multiple devices. For example, if a web server can handle 1000 visits per hour, but our website receives 3000 visits per hour, we need at least three web servers. We can put a load balancer between the internet and the servers. The load balancer distributes the traffic equally among the three servers. If we add a fourth server, then our website will continue to operate even if one fails because the load balancer will continue to distribute traffic among the other three.
We might put each server in a different physical location.
The load balancer itself can become a single point of failure. We can prevent this by- Installing multiple load balancers, each with a unique IP address
- Giving the set of load balancers a hostname
- Registering the hostname with a DNS server and configuring all the load balancer IP addresses under that hostname
- Configuring the DNS server to return all the IP addresses in a lookup request, but to return them in a random order
- Installing multiple load balancers, each with a unique IP address
When a client attempts to connect to a resource
- It looks up the hostname in the DNS server
- The DNS server returns a list of IP addresses corresponding to the hostname (actually corresponding to the load balancers)
- The list appears in random order. The client tries the first IP address on the list. The randomness of the DNS response load balances the load balancers.
- If a load balancer stops working, the client will not receive a response on its IP address. The client will attempt to access the resource by visiting the second IP address on the list.
- The DNS server returns a list of IP addresses corresponding to the hostname (actually corresponding to the load balancers)
- Multipathing – Multipathing is a technique to create more than one pathway between a resource and the clients. Multipathing ensures that if a device in the pathway fails, the resource is still accessible.
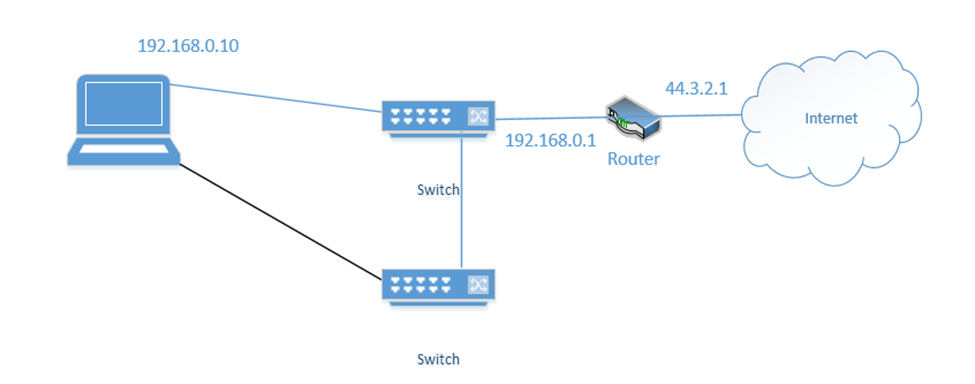
- NIC Teaming – NIC Teaming is a form of load balancing that allows a server to maintain multiple network connections. Remember that a server can have multiple network interfaces. Consider the following server. I have connected it to two switches. Each interface is assigned a different IP address (192.168.0.10 and 192.168.0.11).

You may think that it is fault tolerant because it has two connections. If 192.168.0.11 fails, the server will continue to accept traffic on 192.168.0.11, but this is not fault tolerant because devices connected to the server on 192.168.0.10 will lose their connections. Some clients know to connect to 192.168.0.10 and some know to connect to 192.168.0.11. So, what can we do?
We group the network interfaces into a “team”. We assign the team a single IP address even when the server is connected to multiple switches. This is known as Switch Independent Teaming. One interface is active, and one is passive. The active team assumes the IP address. When the active interface fails, the passive interface takes over and assumes the IP address.
Right now, the bottom link is active with IP address 192.168.0.10
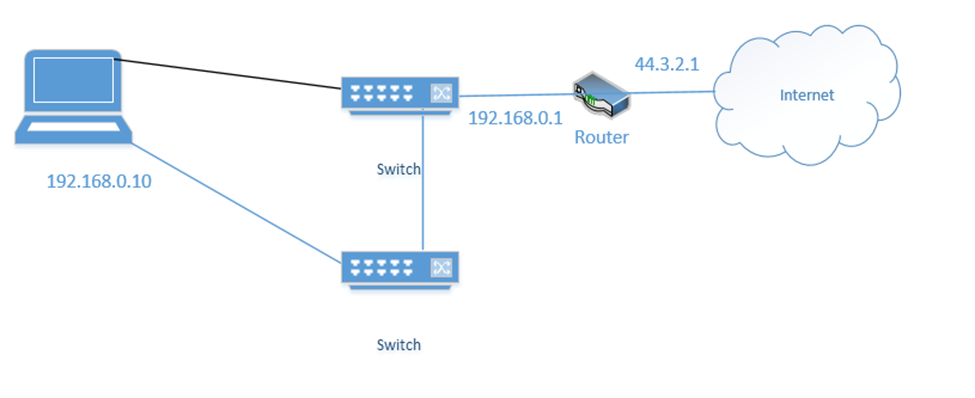
If the bottom link fails, the server assigns 192.168.0.10 to the top link
- Redundant Hardware – Redundant Hardware means that we eliminate single points of failure from our network infrastructure.
- Switches – most devices have only a single ethernet connection (cameras, computers, access points, etc.). Thus, it is not possible to have a redundant ethernet connection unless we have more than one ethernet port on the device.
When we have many devices, we can split them onto multiple switches. For example, if we have twenty wireless access points, we can connect ten to one switch and ten to another switch. In the event of a failure of one switch, half of our wireless access points will continue to function.
High end switches will have two power supplies. That ensures that the switch continues to operate when one fails (or when one power source fails).
We should configure our switches so that we have enough open ports to move connections from a failed switch to a working switch.
- Routers – it is possible to configure two routers in parallel, so that the failure of one router does not affect the network.
- Switches – most devices have only a single ethernet connection (cameras, computers, access points, etc.). Thus, it is not possible to have a redundant ethernet connection unless we have more than one ethernet port on the device.
- Firewalls – it is possible to configure two firewalls in parallel, so that the failure of one firewall does not affect the network. This depends on having enough internet connections
Below is a setup I have made. On the right, we have two internet connections (one broadband and one cellular). Each internet connection connects to both of the firewalls. Each firewall connects to both routers. Each router connects to both switches. Half of the wireless access points connect to one switch and half connect to the other switch. The switches connect to each other, and the routers connect to each other.
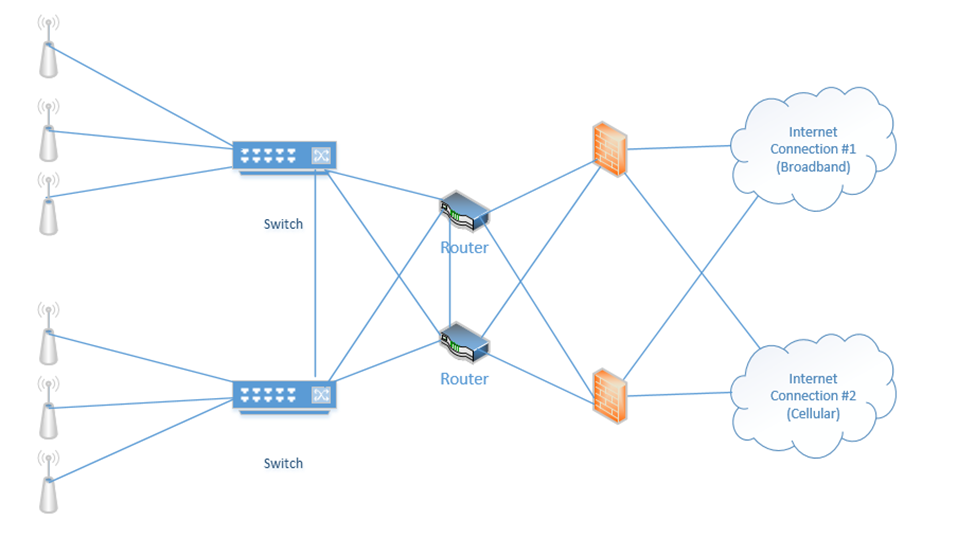
When things are operating normally, the data probably uses the black route. That is, the internet connection #1 is used, the top firewall is used, the top router is used, and both switches are used.
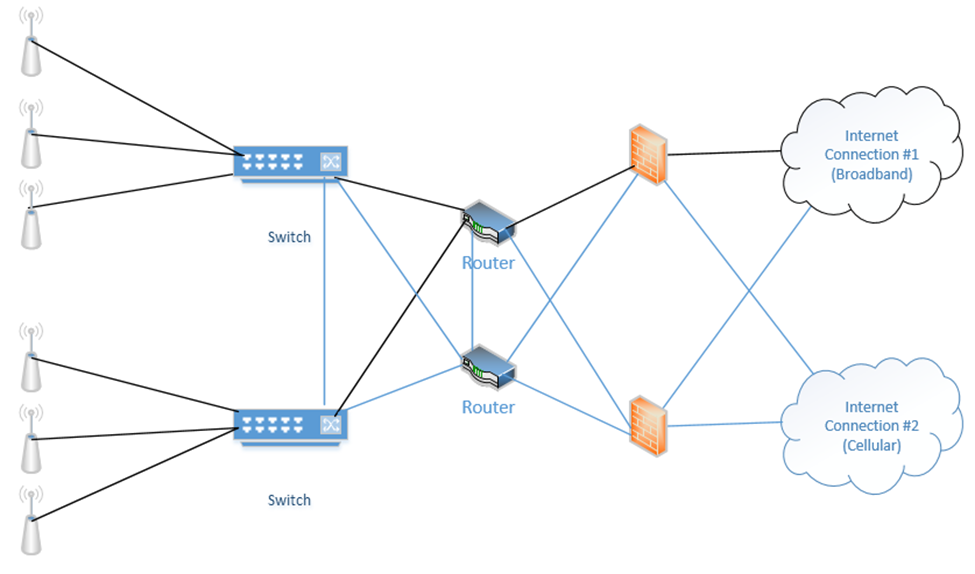
If an internet connection fails, a router fails, and/or a firewall fails, the system will continue to operate.
In my example, we connected each router to both internet connections. One router acts as primary and one router acts as secondary. Remember that every computer on the network has a “default gateway”? That is, if I connect a computer to the switch, how does it know which router to connect to when it wants to access the internet?
We can use the First Hop Redundancy Protocol (FHRP) to create a “virtual router”. We configure FHRP on all the routers. The routers then elect one router to be the primary. The primary router assumes the configuration and becomes the default gateway. If the other routers detect that the primary router has failed, they elect a new router to become the primary. The newly elected router assumes the configuration and becomes the default gateway.
FHRP is a generic idea and can be used to ensure high availability of other services that require a single IP address (such as a web server, DHCP server, e-mail server, etc.). Virtual Router Redundancy Protocol (VRRP) is an FHRP that is proprietary to Cisco devices. Other network equipment manufacturers have their own protocols.
Our devices should each have two power supplies, if possible (the ISP modems usually will not have more than one power supply). We can connect each device to two separate UPSs.
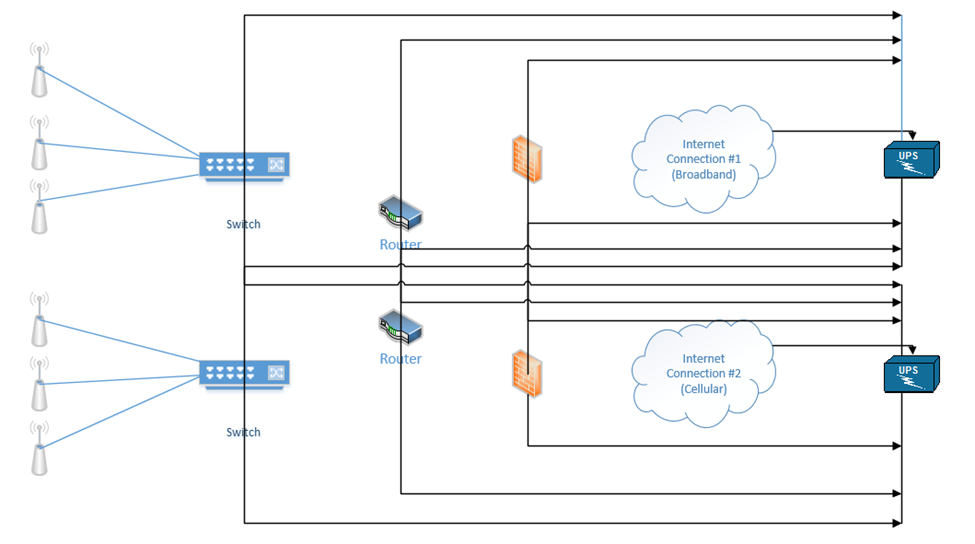
- Facilities and Infrastructure Support – depending on the size of the building and/or infrastructure, we may have some or all of the following
- Uninterruptible Power Supply (UPS) – Between the electrical supply and our equipment, we install a UPS or Uninterruptable Power Supply. In simple terms, a UPS is a giant battery. We connect our equipment to the UPS, and we connect the UPS to the municipal power supply. If the municipal power supply fails (a blackout) or decreases (a brownout), then the UPS takes over. The UPS must be able to take over so quickly that our equipment doesn’t notice and shut down. A UPS may also protect against power surges (when too much power rushes into the building, which could damage the equipment). When the municipal power supply is active, the UPS charges its batteries. When it fails, the UPS supplies the connected equipment from the battery.
The size of the UPS that we need depends on the quantity and type of equipment that we have. When you purchase electrical equipment, the manufacturer must specify how much power it consumes (in Watts). A Watt is a unit of energy consumption. Equipment may use more power when it is busy than when it is idle. Therefore, we should calculate the maximum power consumption of all our equipment.
- Uninterruptible Power Supply (UPS) – Between the electrical supply and our equipment, we install a UPS or Uninterruptable Power Supply. In simple terms, a UPS is a giant battery. We connect our equipment to the UPS, and we connect the UPS to the municipal power supply. If the municipal power supply fails (a blackout) or decreases (a brownout), then the UPS takes over. The UPS must be able to take over so quickly that our equipment doesn’t notice and shut down. A UPS may also protect against power surges (when too much power rushes into the building, which could damage the equipment). When the municipal power supply is active, the UPS charges its batteries. When it fails, the UPS supplies the connected equipment from the battery.
A UPS is rated in Watts. We should not exceed the Wattage rating of the UPS. We should consider purchasing a UPS that can handle 20% to 50% more capacity than we are consuming, in case we need to add new equipment in the future. Also, no UPS is 100% efficient.
The second factor we should consider is the runtime. The runtime tells us how long the UPS can power our equipment for. We should think about how much time we need to properly shut down our equipment. If shutting down the equipment is not an option, then we should think about how much time we need until our power generator takes over.
A UPS can be a small unit that sits on a shelf, a rack-mounted unit, a unit that is the size of a rack, or an independent unit.
This is a small UPS. It might sit on the floor under your desk. It is good for powering a single device or a few small devices. It costs approximately $50. If we have a single switch or router, this might be acceptable.

This is a rack-mount UPS. It takes up 2Us in a rack and is good for powering a rack full of devices. It costs approximately $2000. If we have a single rack full of equipment, this might be acceptable. It would be a good idea to purchase two separate UPSs for redundancy.

This is a full rack UPS. It comes as a full rack and can sit in an MDF or IDF. If we have multiple racks full of equipment, this might be a better solution than using multiple 2U UPSs.

This UPS requires an electrician to install. Equipment will not connect directly to this UPS. Instead, this UPS is connected to an electrical panel. From the electrical panel, we install multiple electrical circuits. We then connect our equipment to the electrical circuits.

UPSs can be much larger. A large building such as a school, shopping mall, or hospital may have a UPS that is connected to the electrical panel and electrical outlets.

- Generator – What if we have a power outage that lasts three days and we need to keep operating, but our UPS only lasts one hour? We install a power generator, which is a device that can produce electricity. When the power outage takes place, the UPS supplies power from its batteries, and the generator produces new power to recharge those batteries.
A typical power generator burns diesel. Generators can be portable or fixed. It is better to have a power generator and not need it then to need it and not have it. The power generator should be maintained regularly to ensure that it is operating and that it contains an adequate supply of fuel. The organization should also make sure that it has a contract to receive additional fuel deliveries during a long power outage.

- Power Distribution Units (PDUs) – Finally, to avoid any single point of failure, it is important to select network devices and servers with redundant power supplies. If we have two UPSs, we connect one power cord from each device to the first UPS, and we connect the second power cord to the second UPS. That way, if a UPS fails, the devices continue to receive power. Most devices with dual power supplies offer power supplies that are hot swappable. Electronics use power that is DC (Direct Current), while a UPS or municipal power supply provides power in AC (Alternating Current). An electronic device will contain an adapter that converts from AC to DC. This adapter may fail during operation. When it is hot swappable, it can be replaced even while the device is powered on.
In a data center with hundreds of devices, it can become difficult to identify which plug goes to which power supply. As a result, manufacturers produce power cables in different colors such as red, green, and yellow. You can use these cables to tell different circuits apart.

- HVAC – HVAC stands for Heating, Ventilation, and Air Conditioning. Engineers typically follow standards published by ASHRAE (American Society of Heating Refrigeration and Air Conditioning Engineers) when they design ventilation systems.
- Heating the room is not typically a concern because the equipment will generate more than enough heat. If the room needs to be heated, we need to decide how the building is heated
- If the building has a boiler (water is heated and pumped throughout the building), we will extend the heating loop into the room. This only provides heat.
- If the building has an air handling unit (air is heated and circulated throughout the building), we extend the duct work into the room. This provides heat and fresh air.
- We can install a portable heater.
- If the building has a boiler (water is heated and pumped throughout the building), we will extend the heating loop into the room. This only provides heat.
- Ventilation is a concern, but it depends on how much time people spend inside the room. If it is an MDF or IDF, it may not require much ventilation. It may be acceptable that the room receives fresh air through the doorway. If it is a data center, then fresh air is required. Fresh air can be pumped in through a make up air unit.
- Air Conditioning is a very important concern because the equipment will generate heat that needs to be removed. The air conditioner can also bring fresh air into the room.
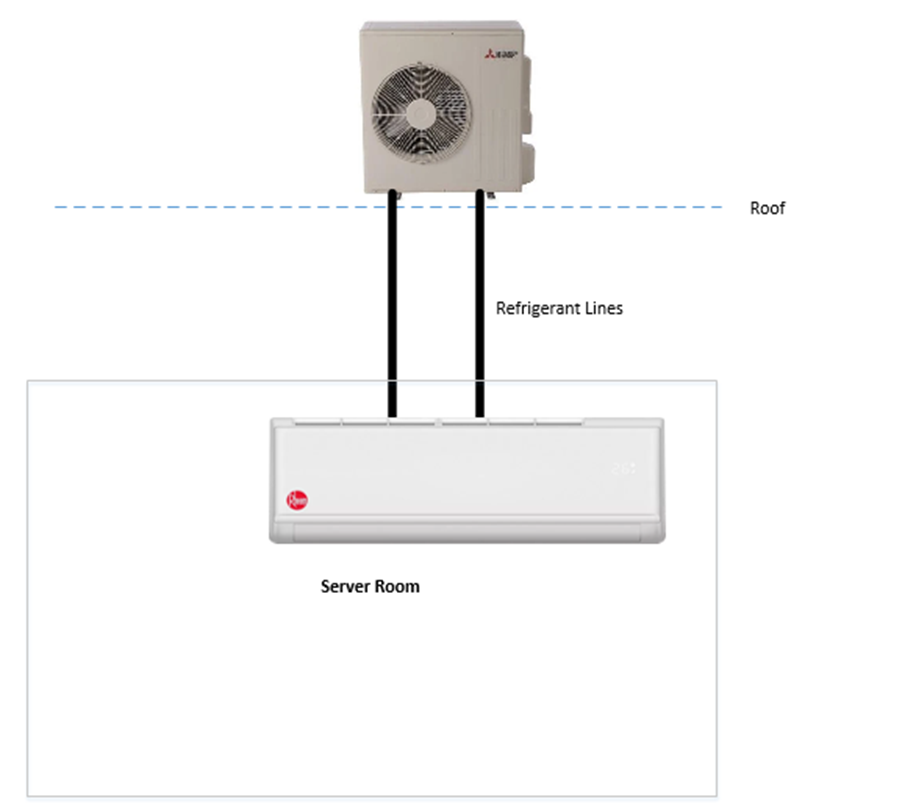
A typical setup for a small server room is to install a split system. It is technically a “heat pump” not an air conditioner because it does not exchange any air with the outside world.
Inside the server room, we install an evaporator unit on the wall. On the roof, we install a condenser unit. The evaporator and condenser are connected with refrigerant lines.
The evaporator unit takes warm air from the room and extracts the heat. It empties the heat into a liquid called refrigerant. The warm refrigerant is pumped to the condenser on the roof, where the heat leaves. The refrigerant cools down and is pumped back into the server room.
- Heating the room is not typically a concern because the equipment will generate more than enough heat. If the room needs to be heated, we need to decide how the building is heated
- Fire Suppression – Fire Suppression is an important concern. How do we stop a fire?
- A fire extinguisher – the most basic fire suppression is to install a fire extinguisher. If a person sees a fire, and they can put it out safely, they can spray it with a fire extinguisher.
A fire extinguisher only prevents small fires that start when a person is watching. We must be careful to use an ABC fire extinguisher, which is one that can put out fires burning wood, flammable liquids, and electrical equipment.
A fire extinguisher must be inspected yearly.
- Sprinkler system – a traditional sprinkler system (also known as a wet pipe system) can automatically put out a fire. It consists of sprinkler heads that are installed throughout the building, connected to water pipes. The water pipes used for the sprinkler system are pressurized. Each sprinkler head contains a small piece of metal that melts under low temperatures (in the photo below it is red). If a fire occurs under the sprinkler head, the metal melts and water is released.
- A fire extinguisher – the most basic fire suppression is to install a fire extinguisher. If a person sees a fire, and they can put it out safely, they can spray it with a fire extinguisher.

- A sprinkler system will put out the fire, but it will damage the equipment. We don’t want the sprinkler head to activate accidentally, and we can use the following measures
- If we install a sprinkler head, we should install a cage around it so that it is not accidentally broken. If somebody breaks the sprinkler head, it will leak water.
- We can install high temperature heads in the server room. Sprinkler heads are manufactured to activate at different temperatures (100°F, 150°F, 225°F, etc). We should select a head that is rated for a high enough temperature so that it does not accidentally activate.
- We do not need to install a sprinkler system in a building that is not combustible (for example a building made of concrete). The actual determination of whether a building is combustible or non-combustible is complicated. It may be possible to build the server room out of materials that are fire rated, and then not have to install sprinkler heads (even if the rest of the building is sprinklered).
- We can install a pre-action system
- If we install a sprinkler head, we should install a cage around it so that it is not accidentally broken. If somebody breaks the sprinkler head, it will leak water.
- Sprinkler system with pre-action – a pre-action system is a system that does not activate until at least two signals trigger the system. We would install a normal sprinkler system. We would then install a heat detector in the server room, next to the sprinkler head. We would install a valve in the pipeline that feeds the sprinkler heads.
If the heat detector is senses heat, it opens the valve and allows water to flow to the sprinkler head. If there is a fire, the sprinkler head melts and water is sprayed onto the fire.
If the heat detector does not sense heat, the valve remains closed and no water reaches the sprinkler head. The sprinkler head will not release any water, even if it is broken.- Dry system – a dry system is a sprinkler system that does not release water, but some other chemical such as Nitrogen or Carbon Dioxide. The gas flows through the entire room and forces the Oxygen out. Since fire needs Oxygen to continue burning, the lack of Oxygen puts out the fire.
A dry system is better because it can penetrate areas that water won’t. For example, if the fire starts at the bottom of the rack, underneath the UPS, the water from the sprinkler will not be able to reach it. The water will fall on top of the rack and puddle underneath the floor.
A dry system also won’t damage equipment.
We will need to install an alarm that warns people when the fire suppression system is activated so that they can quickly leave the room.
3M™ Novec™ 1230 Fluid is a special fluid that can put out a fire 50 times faster than a water-based system without damaging electronics.
The dry systems are more expensive than traditional sprinkler systems.
- Hypoxic system – a hypoxic system is one that reduces the level of oxygen in the room to a point where humans can breathe but a fire cannot start. Normal air is 21 percent oxygen, 78 percent oxygen, and 1 percent other gases.
If we change the air so that it is 15 percent oxygen and 85 percent nitrogen, then humans can breathe but a fire cannot start.
This system is currently not permitted by government regulations unless the employer provides workers with respirators, although studies have shown no adverse health effects.
This system is an active system because it must constantly remove oxygen from the air (fresh air coming from outside will continue to increase the oxygen levels).
- Sprinkler system with water mist – water mist systems are newer, but their popularity is increasing. A water mist system is one that generates an aerosol from the water instead of discharging a high-pressure stream.
The smaller droplets of water cool the air and create steam, which displaces the oxygen. This serves to put out the fire quickly. The mist also reduces the amount of water damage caused when compared with a traditional fire sprinkler system.
Water mist systems are more expensive than traditional systems. They may also be more expensive than pre-action systems.
- What type of fire suppression should you choose? Consider
- The cost of the sprinkler system, the cost of a fire damaging the equipment or burning down the building, the cost of the replacing the equipment, and the building codes
- It is better for the sprinkler system to damage the equipment in the server room than having a fire damage the equipment in the server room and spreading to the rest of the building
- It is always cheaper to design the sprinkler system before the building is built
- Always have a fire extinguisher handy – it is usually required by the local fire code. The fire extinguisher should be mounted to the wall and have a sign that people can see.
- If your building is still under construction or in the design phase and non-combustible, it will not have a sprinkler system
- Consider having the MDF and IDF built out of materials that can withstand a fire for one hour or two hours
- A dry or water mist sprinkler system may be installed only for the IDF and MDF. This will protect the equipment if a fire starts in one of these rooms. The cost of a dry system for a single room will not be much more than the cost of a traditional system for a single room.
- Consider having the MDF and IDF built out of materials that can withstand a fire for one hour or two hours
- If your building is still under construction or in the design phase, and combustible, it will have a sprinkler system
- If your building code allows it, you may build the IDFs and MDF out of materials that can withstand a fire for at least two hours, and not have a sprinkler head in those rooms
- Otherwise, you may be required to extend the sprinkler system into the IDF and MDF. This type of sprinkler system will damage the equipment. It is unlikely that the entire building will have a dry system.
- A dry or water mist sprinkler system may be installed only for the IDF and MDF. This will protect the equipment if a fire starts in one of these rooms, but the cost may be too high. It may cost $30,000 to install a dry system in a single room, so the business must consider whether the cost outweighs the risk.
- If your building code allows it, you may build the IDFs and MDF out of materials that can withstand a fire for at least two hours, and not have a sprinkler head in those rooms
- If your building is existing construction and non-combustible, then the building will not have a sprinkler system
- The business must consider whether they need a fire suppression system for the IDFs and MDF.
- Since only a single room is affected, the cost of a traditional system may be almost as much as the cost for a dry system.
- The business must consider whether they need a fire suppression system for the IDFs and MDF.
- If your building is existing construction and combustible, it will already have a sprinkler system that extends into the IDFs and MDF
- The existing sprinkler system will likely be a traditional system.
- Consider whether you can use fire proof materials to insulate the rooms and remove the sprinkler heads, and whether the cost is worth the reduction in the risk.
- Consider whether the cost of replacing the existing sprinkler heads with a pre-action or dry system is worth the reduction in risk of damaging the equipment
- The existing sprinkler system will likely be a traditional system.
- The cost of the sprinkler system, the cost of a fire damaging the equipment or burning down the building, the cost of the replacing the equipment, and the building codes
- Dry system – a dry system is a sprinkler system that does not release water, but some other chemical such as Nitrogen or Carbon Dioxide. The gas flows through the entire room and forces the Oxygen out. Since fire needs Oxygen to continue burning, the lack of Oxygen puts out the fire.
- Redundancy and High Availability (HA) Concepts – now that we know how to keep a building running in the event of an isolated issue (like a power outage), what do we do to keep the entire business running when an entire building is inaccessible? We can maintain a second site (a second location). There are four types of back up sites
- Hot Site – A hot site is a site that is continually running. With the use of a hot site, an organization has multiple locations that are operating and staffed. For example, an insurance company may have a call center in New Jersey, a call center in Florida, and a call center in California. The insurance company staffs all three centers 24/7. If the California call center is affected by an earthquake, the insurance company diverts calls to New Jersey and Florida, and operations are not disrupted.
In the case of a data center, the organization will maintain data centers in multiple geographic locations. These data centers are connected to each other over WAN links. Data is replicated across multiple data centers, so that damage to one data center does not compromise the data. For example, an insurance company stores customer data in data centers at California, Utah, and Virginia. The Virginia data center is hit by a tornado, but all the data has been replicated to the other two centers. The organization and its customers can continue accessing their data.
A hot site is expensive to maintain. The organization must decide whether it is worth the cost. In the example of the insurance company, they can staff the three sites cost-effectively. A smaller organization (such as a restaurant or warehouse) that operates out of a single location may not find it cost-effective to operate a second site.
Key staff (like the CEO) who operate from one site can be moved to the hot site during a disaster.
- Cold Site – A cold site is a location that does not contain staff or equipment. An organization hit with a disaster must send employees to the cold site, bring in supplies, and configure equipment. The cold site does not contain any data; the organization must restore its data from back up.
A cold site is cheaper to operate than a hot site. In the event of a disaster, the cold site can be used to operate the business. The cold site may be an empty office, an abandoned warehouse or a trailer.
Organizations such as Regus provide immediate short-term office space that companies can rent in the event of a disaster.
- Warm Site – A warm site is a compromise between a cold site and a hot site. A warm site may contain some hardware and preconfigured equipment. The organization may need to bring in staff and/or specialized equipment for the warm site to become operational. The warm site may contain copies of data, but they will not be current.
- Hot Site – A hot site is a site that is continually running. With the use of a hot site, an organization has multiple locations that are operating and staffed. For example, an insurance company may have a call center in New Jersey, a call center in Florida, and a call center in California. The insurance company staffs all three centers 24/7. If the California call center is affected by an earthquake, the insurance company diverts calls to New Jersey and Florida, and operations are not disrupted.
- Cloud Site – A cloud site is where we replicate our physical infrastructure in the cloud. An organization may want to maintain physical control of its data and devices but may compromise during a disaster and redirect employees to the cloud.
The cloud will likely be set up as a warm site that can mimic the infrastructure and data of the existing operation. Employees can connect to the cloud site from home or from an actual cold/warm/hot site.
We should also make sure to maintain multiple internet connections at each site
- Active-Active vs Active-Passive
- An Active-Active connection is where we set up two or more internet connections and use both or all of them at the same time. The router will choose which internet connection to route traffic to based on an algorithm.
- An Active-Passive connection is where we set up two or more internet connections and use only one of them. The internet connection that we prefer to use is called the primary internet connection. The other internet connection is called the failover.
- Some scenarios that we can have
- WAN and Broadband
- The active connection is a WAN link – traffic between offices passes over the WAN
- The second active connection is a broadband link – traffic from an office to the internet passes through the broadband link. This is good when we have an expensive WAN and we don’t want to waste it on traffic that does not need to pass through it
- If the WAN fails, the router can create a VPN tunnel to the other offices through the broadband connection
- The active connection is a WAN link – traffic between offices passes over the WAN
- Broadband and Cellular
- The active connection is a broadband. If the business has only one location, all of the traffic passes through the broadband.
- If the business has multiple offices, they might set up an SD-WAN. Traffic to another office passes through the broadband and into the SD-WAN. Traffic to the internet passes through the broadband and straight into the internet.
- If there are two or more broadband providers in the area, we might set up an SD-WAN with two broadband connections.
- The failover connection is a cellular modem. If the broadband fails, traffic passes through the cellular modem.
- The active connection is a broadband. If the business has only one location, all of the traffic passes through the broadband.
- WAN and Broadband and Cellular
- The active connection is a WAN link – traffic between offices passes over the WAN
- The second active connection is a broadband link – traffic from an office to the internet passes through the broadband link.
- A cellular link provides back up for the WAN and the broadband. This is good when the same ISP provides the WAN and the broadband (i.e. where physical damage to the wiring would shut down both the broadband and the WAN)
- The active connection is a WAN link – traffic between offices passes over the WAN
- WAN and Broadband
Some ways that we can measure our recovery
- Mean Time to Repair (MTTR) – MTTR, or the mean time to repair is the average time from when a failure is detected/reported until it is repaired. For example, if a server breaks down at 11AM and is repaired at 1PM, the time to repair is two hours. If we have multiple breakdowns, we can average them to obtain the MTTR.
The MTTR is the time to resolve to the issue, not the time to respond the issue. For example, if a server fails, and a repairman arrives within three hours, but it takes an additional hour to troubleshoot and repair the issue, then the repair time is four hours.
When determine an MTTR, the shorter the MTTR the more money it will cost. To ensure a short MTTR, the we (or our vendor) may need to have more technicians on call whether they are performing useful work or not, and the we (or our vendor) may need to stock spare parts whether or not they are required.
Different types and severities of incidents can have different response times. The organization must weigh the response time against the impact to the business. Critical incidents may require response times measured in hours while trivial issues may allow response times measured in days or even weeks.
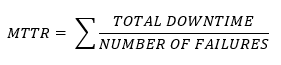
The system’s availability is the time that it is available.
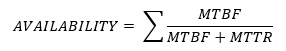
- Mean Time Between Failure (MTBF) – MTBF is the Mean Time Between Failures. This is the average amount of time between failures of a device. Some devices can be repaired, and some devices cannot. For example, a hard disk drive that fails irreparably after 300,000 hours has a MTBF of 300,000 hours. A computer server that fails (but can be repaired) after 100,000 hours and then again after 300,000 hours has an MTBF of 200,000 hours (average of 100,000 and 300,000).
The MTBF of electronics and industrial equipment is usually measured in operating hours (since a device sitting on a shelf is less likely to fail). Some devices have a failure rate that is measured in cycles or per use (for example airplanes are rated based on the number of times they take off and land, and not the amount of time they spend in the air – take offs and landing put more stress on the airplanes’ components than the actual flying).
A manufacturer will should disclose the MTBF on each device that they manufacture so that customers can make informed purchasing decisions. If a device is inexpensive but has a high failure rate, then the long-term cost may be much higher.
For example, if an organization purchases hard drives with a 300,000-hour MTBF, but they have deployed 100,000 hard drives, then they can expect that (on average) one hard drive will fail every three hours (or about eight per day). They can use this to plan their replacement strategy.
Electronic devices usually fail on what is called a bathtub curve (high failure rate at the beginning and end of their life span, and low failure rate in the middle).
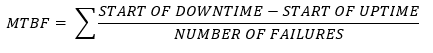
- Recovery Time Objective (RTO) – The Recovery Time Objective is how much time we have from the disruption to get things back to normal. If we exceed the RTO, then the business will begin to suffer severe consequences.
For example, a chemical plant I worked with had an RTO of four hours. If a critical issue was not resolved within four hours, the plant would lose one million dollars per hour after that. That is not to say that they did not suffer any consequences the first four hours, just that they were tolerable.
The less time we have to restore our services, the more the restoration will cost. We must weigh the cost of the recovery against the cost of the harm to the business. - Recovery Point Objective (RPO) – The Recovery Point Objective is the amount of data the business can afford to lose without suffering severe consequences. It is typically measured from the time of the last back up until the incident occurs.
For example, if we can afford to lose a maximum of 24 hours worth of data, then we should back up our data at least once per day. If we back up our data at 12:01AM, and we have a crash at 11:59PM, we would lose 24 hours of data. If we back up our data once per week at 12:01AM on Monday and we have a crash at 2:00PM on Friday, we would lose several days of data, which would be unacceptable.
We must weigh the cost of the back ups against the cost of losing the data. - Availability – The system’s availability is the time that it is available to the end users. It can be calculated from the MTBF and the MTTR.
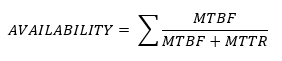
- Network Device Backup/Restore
- Configuration – we should maintain a back up of the configuration of each network device. This can be completed automatically each time a change is made. In the event that a device is replaced, the configuration can be easily transferred to the new equipment.
We should always make a back up of the configuration before making any changes.
- State – it is more difficult to back up the state of a network device. The state includes things like active sessions and connections, MAC address tables, and routing tables. If we are using a software defined network, then we can take snapshots of the device states and restore them to exactly the way they were before.
- Configuration – we should maintain a back up of the configuration of each network device. This can be completed automatically each time a change is made. In the event that a device is replaced, the configuration can be easily transferred to the new equipment.